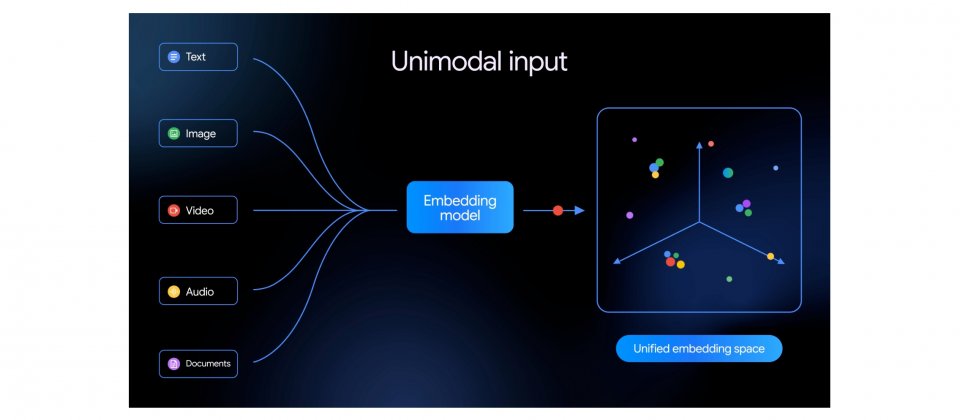
Google公布第一款原生多模態嵌入模型Gemini Embedding 2,目前透過Gemini API與Vertex AI以公開預覽形式提供。相較Google先前以文字為主的嵌入模型,Gemini Embedding 2可將文字、圖片、影片、音訊與文件映射到同一個向量空間,讓開發者可用相同基礎模型處理跨媒介的檢索、分類與語意比對工作。
Google擴展原本嵌入模型能力,從文字檢索進一步擴大到多模態內容處理。官方表示,新模型可支援超過100種語言,並可處理圖文混合等交錯輸入,讓系統不只辨識單一媒介內容,也能理解不同資料型態之間的語意關聯。對企業建立檔案搜尋、影音資產管理、知識庫檢索或檢索增強生成(RAG)系統時,藉由單一向量空間設計有助於減少原本分散的資料處理流程。
Gemini Embedding 2可處理最長8,192個輸入詞元(Tokens)的文字輸入,每次請求最多可接受6張PNG或JPEG圖片,支援最長120秒的MP4或MOV影片,也可直接處理音訊而不需先轉成文字,另可直接嵌入最長6頁的PDF文件。Google也延續先前模型採用的Matryoshka Representation Learning訓練方式,讓嵌入向量即使維度縮減,仍能保留主要語意,官方建議3,072、1,536與768維度作為品質較高的選項。
與Google先前文字嵌入模型相比,Gemini Embedding 2的更新重點不只在版本迭代,而是把嵌入範圍從文字語意表示,擴大到圖片、影片、音訊與文件的原生多模態表示。Google表示,Gemini Embedding 2在文字、圖片與影片任務上優於既有領先模型,並新增語音處理能力,擴大多模態覆蓋範圍。
熱門新聞

2025-06-02

2026-03-13

2026-03-14

2026-03-13

2026-03-12

2026-03-13

2026-03-13

2026-03-13