
Akamai
全球IT服務與資料中心在2025年大規模當機事件頻傳,令人意外的是,當中不乏許多企業與組織重度依賴的大型公有雲業者,如Cloudflare、AWS、Azure、Google Cloud,這些事件不僅嚴重影響這些服務商的商譽,也促使眾人反思是否過度高估公有雲的可靠度。然而,在一連串大規模服務停擺事故發生期間,仍有大型雲端業者正常運作,而且已建立4年以上未發生重大當機的紀錄,這家廠商正是以提供CDN服務、資安服務與邊緣雲端服務著稱的Akamai。
在本週舉行的年度記者會上,Akamai副總裁暨亞太區總經理李昇表示,他們協助全球指標性企業達成99.999%(5個9)的高可靠度標準,他強調可靠度與可用性是非常關鍵的,因為作為平臺化的服務,Akamai除了功能面的發展,每年也投入很多資源,不停提升整個平臺的可用性、穩定性、韌性、靈活度,因為隨著平臺持續添加新的功能型應用,架構勢必越來越複雜,每做一次版本更新或升級,也將面臨更多風險,越來越難控制,對此Akamai會確保整個平臺達到5個9的可靠度,而這樣的服務表現優於同類廠商。
對比其他公有雲業者的可靠度服務等級,多數廠商的設定在99.9%與99.99%之間。例如,就CDN而言,AWS的Amazon CloudFront是99.9%,Azure Front Door是99.99%,GCP Cloud CDN是99.95%。
李昇說,大家很少在網路上看到Akamai發生重大事故的消息,但對於Akamai而言,沒消息就是好消息,他重申背後有強大的平臺工程團隊,持續調校與維護全球網路服務,使得Akamai服務的可靠度在業界獲得很多認可。

剖析發生全球IT大當機事故的原因,以及得以倖免於難的關鍵
Akamai做對了哪些事情?Akamai資深技術顧問王明輝表示,早期他們開發CDN架構的時候,就將可靠度作為公司發展的重要DNA,雖然在2025年很多大型的平臺出現中斷的問題,影響很多客戶的營運,但Akamai從2021年7月至今,將近5年皆未發生平臺斷線的事件,對於大型的公有雲來說,是個非常難得的紀錄。
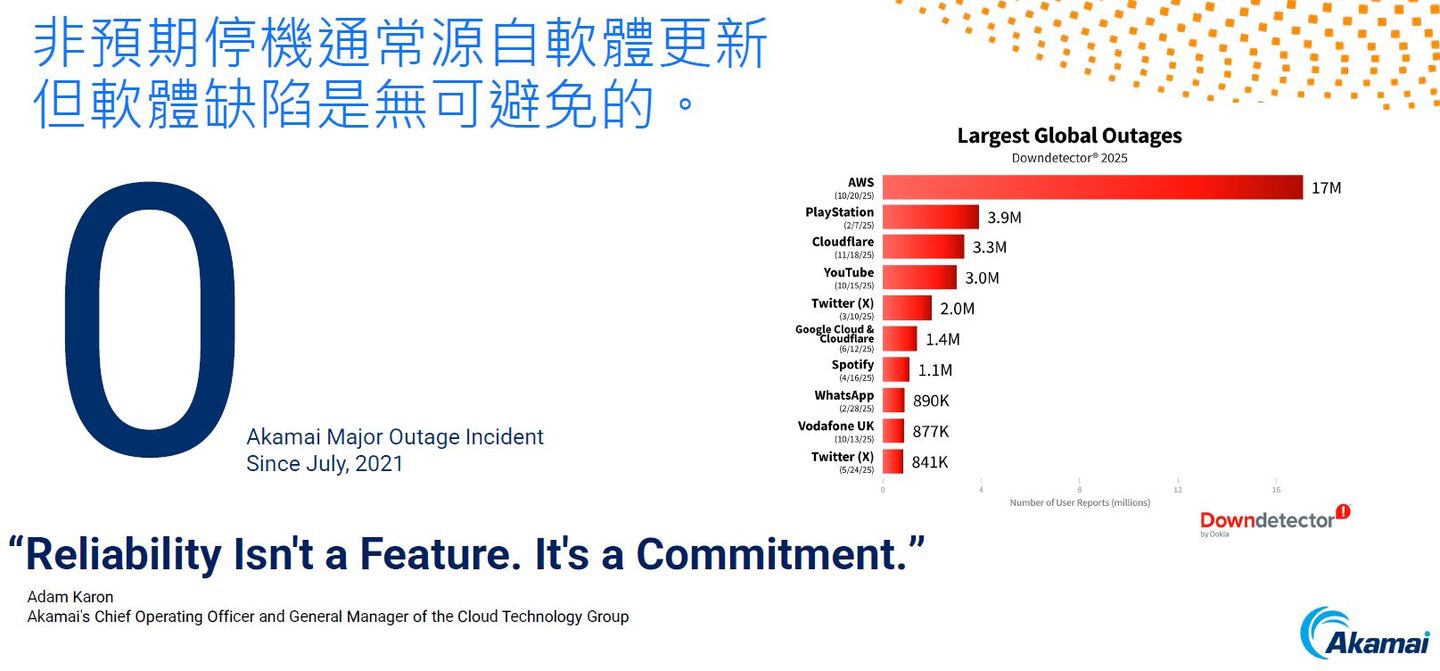
他坦言,這並不代表Akamai開發的軟體並沒有任何bug,任何大型的雲平臺一定都會有,但問題在於能否有效控制、監控、自我修復,將bug的影響控制在最小的範圍裡面,也是大型雲平臺必須追求的方向。
為何會發生大型雲端服務中斷?王明輝認為有四大原因。
首先,是軟體有缺陷,競態條件、錯誤配置或邏輯缺陷引入了不穩定性。第二,後續發生檢測機制失效的問題:原本應該監控bug的檢測系統,卻臨時失效了。第三,在這樣的情況下,連鎖反應開始擴散到上下游的不同元件。第四,最終造成整個系統的崩潰(無法運作)。系統一旦出問題,平常不會連線或存取的使用者,可能此時反而都想要進來看看。例如,出現某廠商系統或服務斷線的傳聞,全臺灣可能有一半以上IT的人員都會嘗試連線,確認是否真有其事,但其實這會造成更大的網路流量負擔,加速整體平臺崩潰。

他強調,Akamai設計可靠度架構時,要做的並非防止bug產生,因為bug就是會發生,而是設計有效偵測這類狀況且能自我修復的系統。這當中有五個主要的核心要素,第一是建立具有高可用性的架構,Akamai透過全球設置大量邊緣節點,防止單一節點故障的問題;第二是設計能自動發現與修復問題的系統,而且這個系統本身也必須可靠,並非平臺用了高可用性架構之後,檢查運作狀況的系統就能鬆懈,因為這類系統一旦失效、無法及時發現問題的時候,也會導致嚴重的影響;第3是有效治理,在大型平臺裡面,有非常多的開發團隊進行業務的開發,如何促使多個IT開發者遵循相同的治理策略,並且採用最佳實踐化的方式設計架構,會是相當困難的挑戰,因此在Akamai的企業文化中,會自我要求採用高可用性的思維方式,去設計所有的軟體架構。

第四是變更的安全性。有別於其他雲廠商,Akamai若要執行任何的軟體變更作業,都會在小範圍先試行,王明輝表示,公司在全球有超過4千個節點,會在一部分節點進行間接發布,一旦出現問題,他們可以及時發現與阻擋,並且實施組態設定復原(configuration rollback)的機制,將影響的範圍與程度控制到最小,提升危機管理能力,而且,這樣的概念也跟微分段(Micro-segmentation)相通,因為在微分段的實作上,同樣會設法將這個風險把它控制到最小範圍的部分,就不會造成企業整體崩壞的狀況。
第五則是實踐企業可靠度文化,Akamai 副總裁暨技術長James Kretschmar在去年The ITPro Procast探討雲端大當機的專訪強調,建立可靠度的文化至關重要,如果我們正在做上述的事情,而且每天都這麼做,就會自然而然地成為組織的文化與常態,因此,我們需要營造這種文化,而且有時做著做著就達到目標。

呼籲各界認知到平臺可靠度不只是特性與承諾,更牽涉到客戶的業務成敗
關於2025年發生全球多家雲端服務大當機事故,Akamai營運長暨雲端科技事業群總經理Adam Karon曾有感而發,表明他們也曾經歷類似狀況,直言系統不可靠的代價不僅是技術層級的故障,而是影響整個組織的業務挫敗與連鎖反應。
他認為,隨著技術不斷演進,可靠度越來越重要,但兩者的差距正在加大而非縮減,Adam Karon也特別點出IT大當機必然且頻繁發生的原因。他用二分法區隔兩種IT平臺,一種是定義規模與穩定性的核心平臺,將可靠度視為商業模式的根本,聚焦可靠度創新的精益求精,提供可預測的效能、安全性、可用性,其他則是將本身視為商品的平臺,業者積極宣傳本身的快速創新與持續部署,目的是不斷吸引眾人關注與引起興趣,並輕忽可靠度,視其為成本中心。
有些企業為了使用成本更低廉的雲端服務,而接受每一季中斷多次服務的代價,但Adam Karon認為,認可線上業務停擺每季停擺一小時的收入損失,這不僅意味著組織承擔了技術債,也代表組織向競爭劣勢低頭,他強調,身處顧客體驗決定誰是市場贏家的時代,可靠度不該被犧牲。
最後他重申完美的持續運作(Perfect uptime)並不存在,但接近完美(near perfect)與夠好(good enough)的差距,可透過收入損失金額與不滿意服務的用戶數量等量化指標得知的,當然,對於品牌傷害的影響更是難以估計,而Akamai的立場是提供最佳的可靠度,即使這麼做將使公司面臨更困難的挑戰、更昂貴的成本負擔、更複雜的技術架構設計,但他們很清楚客戶的業務不能只是建立在彼此的承諾之上,而要仰賴的是持續穩定運作的平臺。
熱門新聞

2026-03-06


2026-03-11

2026-03-12

2026-03-13


